💬 Send me feedback about this article
My mom occasionally needs to transcribe the audio embedded in PowerPoint slides for her job. Each slide often contains a voiceover, and the manual transcription process used to take her weeks. I built a small tool — first in Python with Reflex, then later as a pure client-side JavaScript app — that automates the entire process using OpenAI’s Whisper API. In this post, I’ll break down the problem, my approach, the two iterations of the system, and a few lessons learned.
The Problem: Transcribing Audio in PowerPoint
My mom often works with PowerPoint presentations that have embedded audio — one clip per slide (see the figure below). The goal: transcribe all the audio into editable text.
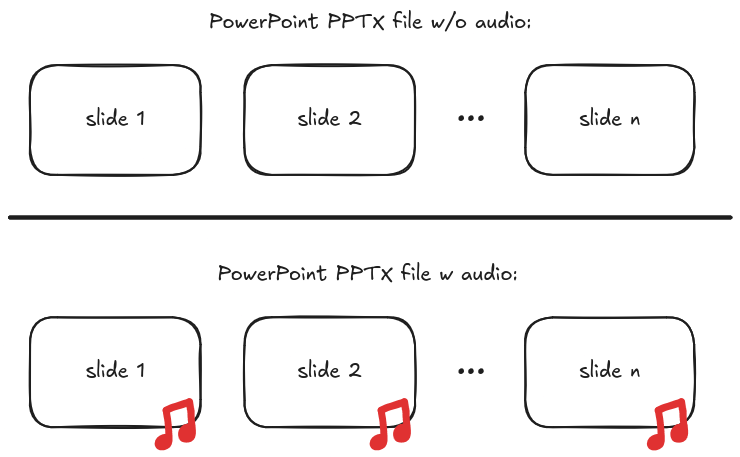
Schematic diagram showing two PowerPoint slide decks, one with and one without audio.
PowerPoint doesn’t expose this audio cleanly, and there’s no built-in way to transcribe it. The manual workflow involved opening each slide, playing the audio, and typing it out by hand. For decks with 30–40 slides, this could easily take a week or more.
The real bottleneck was that each clip required multiple listen–type–rewind passes, with no way to batch the work.
The Task: Use AI to Help my Mom
Watching this unfold, it was obvious that most of the effort was mechanical — listen, type, rewind, repeat. A machine could do that.
That’s when I started thinking: AI should be able to help here. Speech recognition has come a long way, and models like OpenAI’s Whisper had recently become accessible via API. The idea was simple: extract the audio from each slide, feed it into Whisper, and return clean text grouped by slide.
From a technical standpoint, the task broke down into three parts:
- Parse the .pptx file and extract all embedded audio.
- Transcribe each audio clip using an AI model.
- Present the output in a way that’s easy to edit or reuse.
This seemed very doable with off-the-shelf tools. My goal was to build the simplest possible version to reduce my mom’s manual workload — and avoid becoming her permanent tech support.
V1: A Quick Python App Using Reflex + Whisper
The first version of the app used Reflex (formerly Pynecone), a Python framework that compiles into a React frontend. Since I was already comfortable in Python and wanted to move fast, it was a great fit.
Tech Stack for V1:
- Frontend: Reflex (Python, compiles to React)
- Backend: Dockerized FastAPI (local only)
- Transcription: OpenAI Whisper API
- Input: .pptx files uploaded manually
- Output: plain-text transcripts grouped by slide
How it worked:
- .pptx files are just ZIP archives.
- Audio files (typically .m4a or .mp3) are extracted from the ppt/media folder.
- Each audio file is passed to Whisper for transcription.
- Transcripts are grouped by slide and returned as a downloadable .txt file.
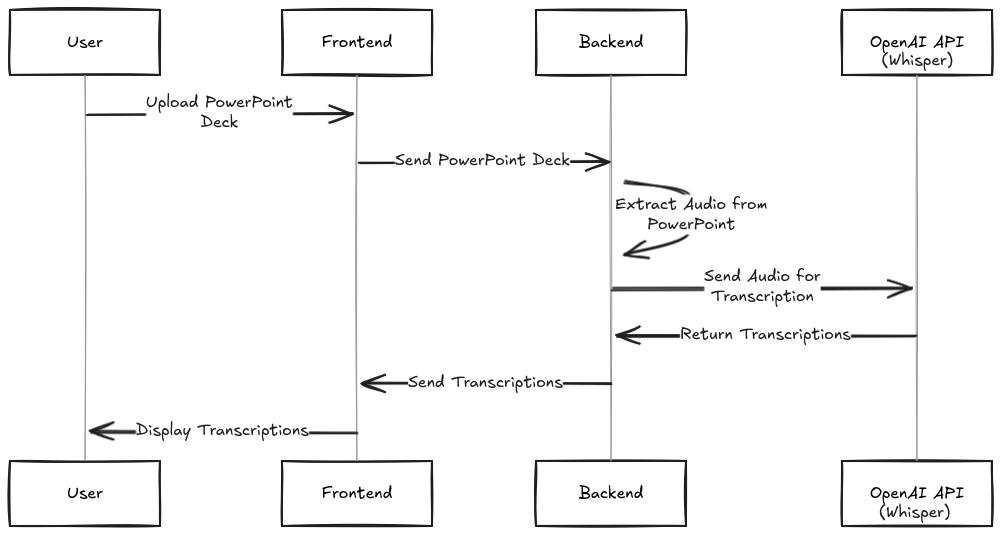
System design diagram for version 1. The user uploads a PowerPoint deck through the frontend; the backend extracts audio, sends it to OpenAI Whisper for transcription, and returns the text to the frontend.
This worked well as a proof-of-concept — but the workflow was clunky. My mom had to send me the file, I ran the app locally in Docker, then sent her the results. Definitely not ideal.
V2: Going Fully Client-Side with Vanilla JS
For the second version, I removed the backend completely.
Why?
- I didn’t want to host or maintain a server.
- The Whisper API could be called directly from the browser.
- The only “secret” needed was the OpenAI API key, which I could hand over manually. (My mom doesn’t know what an API key is, but she’s fine pasting it in if I give it to her.)
Tech Stack for V2:
- Pure HTML + JavaScript (no frameworks)
- Deployed as a static site
- Transcription via Whisper, called from the frontend
- User supplies their own API key
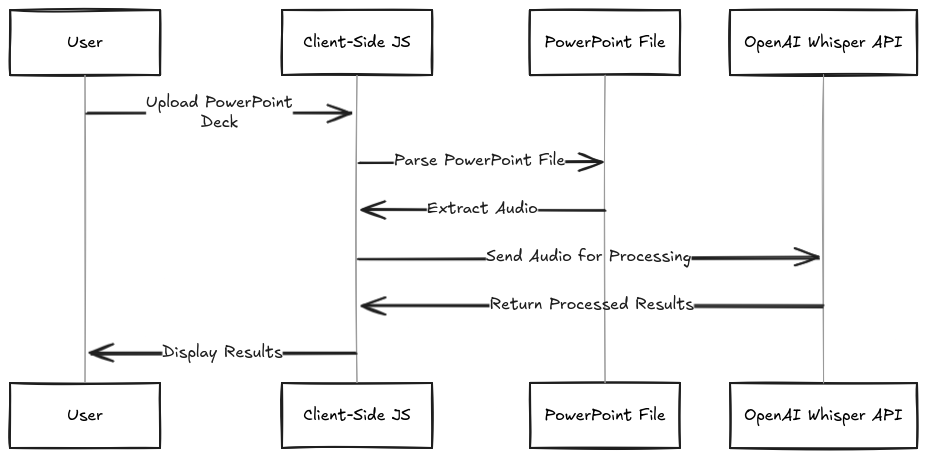
System design diagram for version 2. Everything happens client-side: the user uploads a PowerPoint deck, the browser parses and extracts audio, sends it to Whisper, and displays the results — no server required.
Here’s what the app looks like (or try it here):
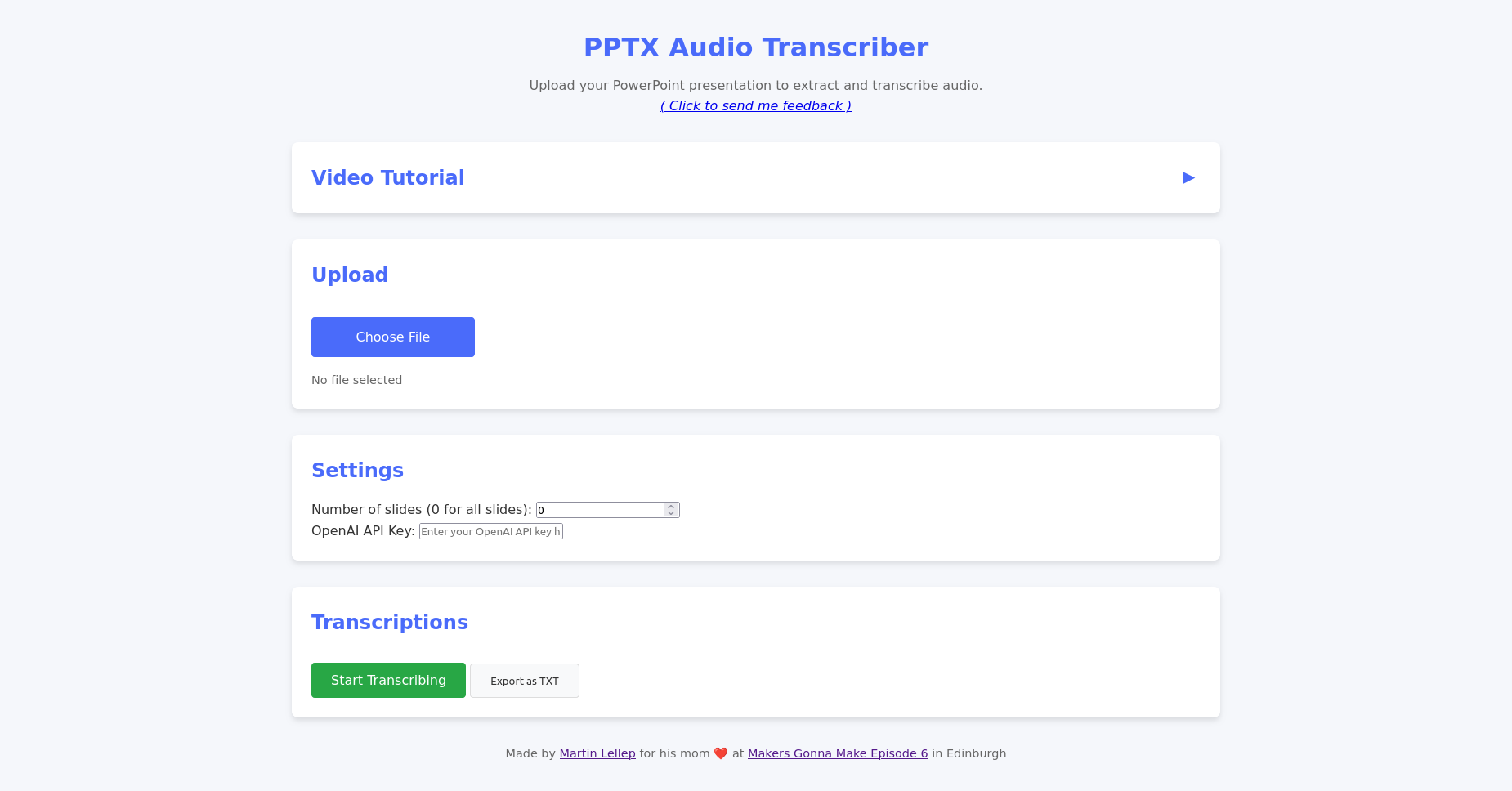
Screenshot of the deployed app. Upload your PowerPoint deck, paste your OpenAI API key, and start transcribing — all in a few clicks.
In this version, my mom uploads a .pptx file, the browser (using JSZip) unpacks it, extracts audio clips, and sends them to Whisper one by one. Transcriptions appear inline and are available for download.
Security note: The API key is never stored or logged. Everything happens in-browser. It’s not perfect UX, but for a one-user internal tool, it’s good enough.
Results and Reflection
Today, my mom completes what used to take a week in a couple of hours. The app is reliable, simple, and basically maintenance-free.
A few quick lessons from the project:
- .pptx files are just ZIPs with predictable structure — very convenient.
- Client-side-only apps are underrated for small tools like this.
- Whisper is impressively robust, even with low-quality or mumbled audio.
- Reflex is a fun and productive way to build full-stack apps in Python.
This was a super satisfying project: practical, personal, and technically interesting without ballooning in scope.
Next steps: None. Mission accomplished. 🫶
💬 Feedback? I’d love to hear it
Big thanks to Makers Gonna Make Edinburgh and Peter for organizing the Saturday hackathons where I built this! ❤️